Enhancing Self-Consistency and Performance of
Pretrained Language Models with NLI
Joseph J. Noh
William S. Armstrong
Ananth Agarwal
Patrick Liu
Stanford University
2022 Conference on Empirical Methods in Natural Language Processing (EMNLP)
Abstract
While large pre-trained language models are powerful, their
predictions often lack logical consistency across test inputs.
For example, a state-of-the-art Macaw question-answering (QA)
model answers Yes to Is a sparrow a bird? and
Does a bird have feet? but answers No to Does
a sparrow have feet?. To address this failure mode, we
propose a framework, Consistency Correction through Relation
Detection, or ConCoRD, for boosting the consistency and
accuracy of pre-trained NLP models using pre-trained natural
language inference (NLI) models without fine-tuning or re-training.
Given a batch of test inputs, ConCoRD samples several candidate
outputs for each input and instantiates a factor graph that
accounts for both the model's belief about the likelihood of
each answer choice in isolation and the NLI model's beliefs
about pair-wise answer choice compatibility. We show that a
weighted MaxSAT solver can efficiently compute high-quality
answer choices under this factor graph, improving over the
raw model's predictions. Our experiments demonstrate that
ConCoRD consistently boosts accuracy and consistency of
off-the-shelf closed-book QA and VQA models using off-the-shelf
NLI models, notably increasing accuracy of LXMERT on ConVQA by
5% absolute.
TL;DR: We introduce ConCoRD, a method that extracts more internally consistent (and ultimately
more accurate) predictions from a pre-trained language model for a batch of
test inputs, without fine-tuning!
An Overview of ConCoRD
ConCoRD processes a batch of test inputs in three steps. In
step one, ConCoRD samples several candidate outputs for
each test input from the base model. In a question-answering setting, we sample several
candidate answers for each test question, perhaps using techniques like
diverse beam search.
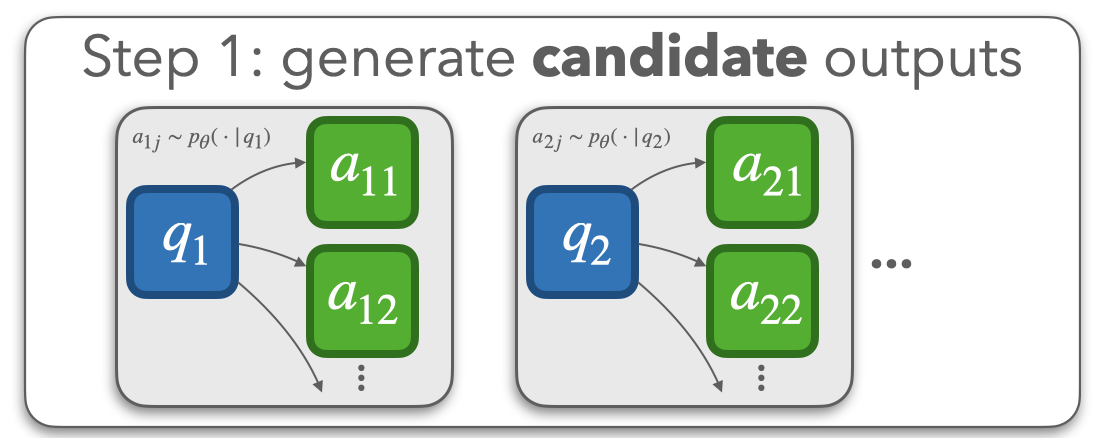
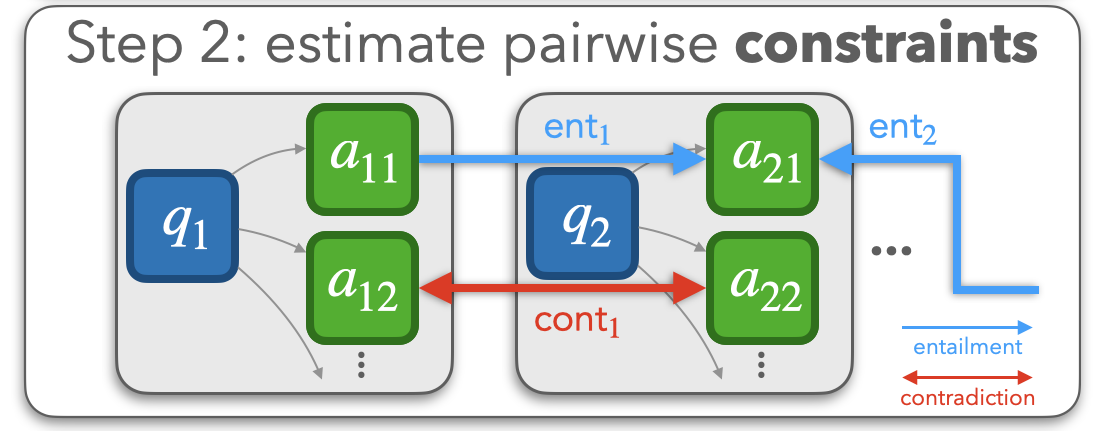
In step two, ConCoRD runs an off-the-shelf Natural Language
Inference (NLI) model on pairs of model beliefs, where a model
belief corresponds to a pair of (input, candidate output). The NLI model
estimates the likelihood that an entailment relation, contradiction relation,
or no relation exists between a belief pair. For the pairs where an entailment
or contradiction relation is likely, we intuitively need to balance the base
language model's original confidence scores for each answer with the need to
satisfy the relationships detected by the NLI model.
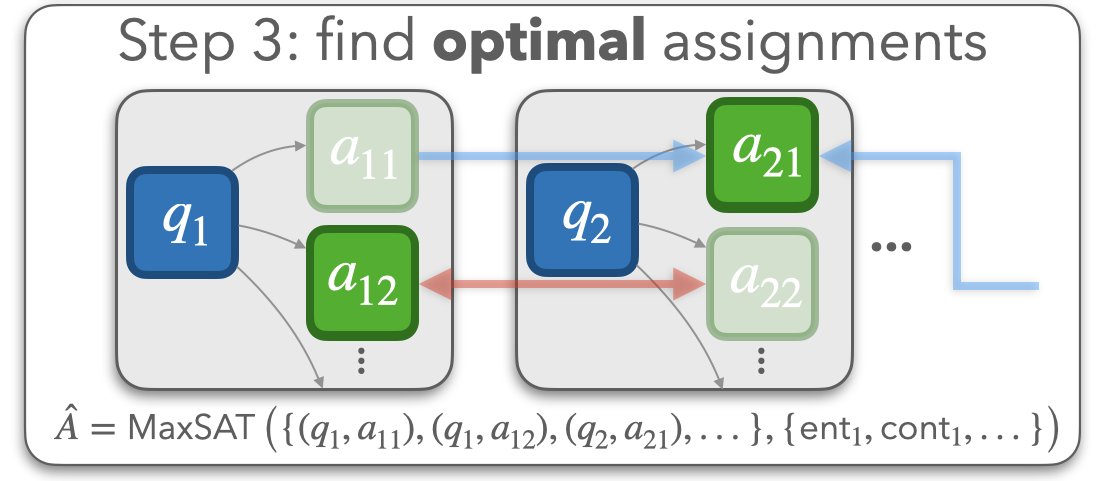
In the step three, ConCoRD uses a MaxSAT solver to find the approximately
optimal choices of model outputs that balances the base model's original confidence
and the compatibility between answers, as determined by the NLI model. This optimization
problem is equivalent to finding the maximum probability assignment of the variables
in a factor graph that contains unary factors reflecting the probability that the base
model assigns to each answer and binary factors reflecting the probability that the NLI model
assigns to an entailment or contradiction relation existing between a pair of answers.
How does ConCoRD create a factor graph from the predictions of our base model and NLI model?
The example below shows a factor graph for a batch of two test questions: What
is the capital of Afghanistan? and What is the capital of Georgia? ConCoRD
defines a binary variable zij representing the truth of each candidate
answer aij. The factor graph is defined over these binary truth variables. In
addition to unary factors for the probability assigned to each answer by the
base model and binary factors representing the NLI model's predictions, ConCoRD includes
mutual exclusivity (XOR) factors among the set of answers for a given question (to represent the
constraint that the binary truth variable must be True for exactly one answer per problem).
ConCoRD converts this factor graph into a weighted MaxSAT problem, for which optimized solvers exist.
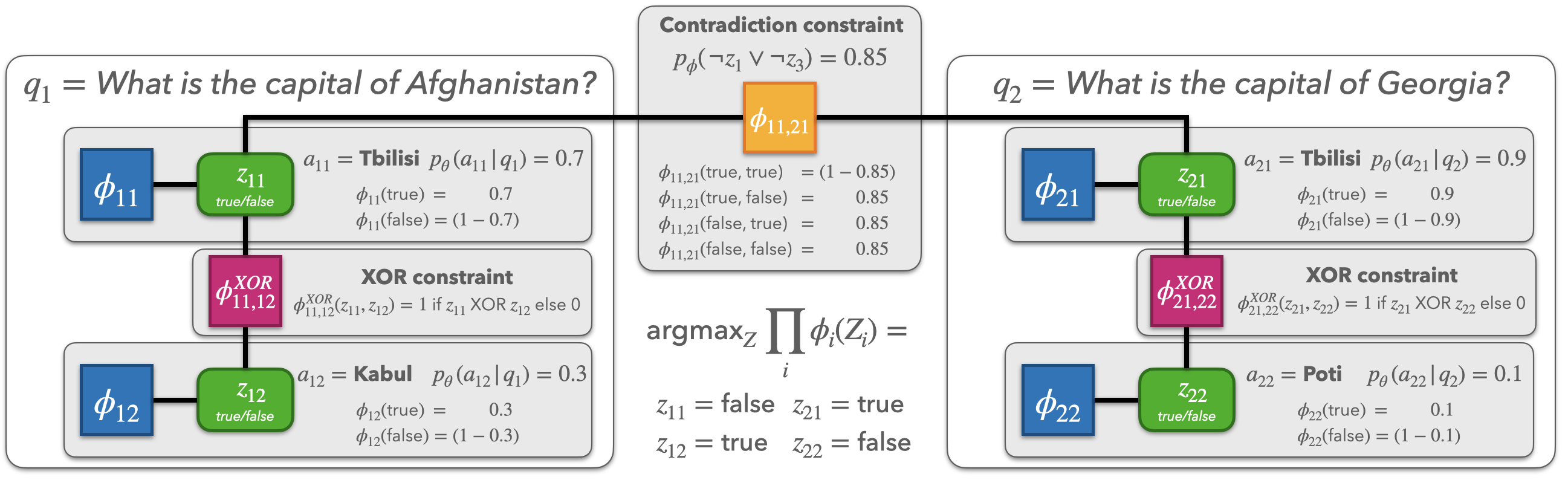
In general, we don't need to assume that all test questions within a batch are closely
related; we use a pair of questions that are closely related here only for illustrative
purposes. In practice, the NLI model is responsible for the identifying pairs of model beliefs for which
a relationship actually exists.
Citing the paper
@inproceedings{mitchell2022enhancing,
title={Enhancing Self-Consistency and Performance of
Pretrained Language Models with NLI},
author={Mitchell, Eric and Noh, Joseph J. and Li, Siyan and
Armstrong, William S. and Agarwal, Ananth and
Liu, Patrick and Finn, Chelsea and Manning, Christopher D.},
booktitle={Proceedings of the 2022 Conference on Empirical
Methods in Natural Language Processing (EMNLP)},
url={https://ericmitchell.ai/concord.pdf},
year={2022},
publisher={Association for Computational Linguistics}
}
|
Acknowledgements
The authors would like to thank the anonymous reviewers for their helpful feedback
during the review period, Gabe Mudel, Julie Wang, Cameron Tew, Anthony Tzen, Kevin Yang,
and Ian Ng for helpful discussions and assisting with exploratory experiments early on
in the project, and Nora Kassner for providing helpful early guidance in configuring the
BeliefBank experiments. CF and CM are CIFAR Fellows. EM gratefully acknowledges funding
from the Stanford Knight-Hennessy Graduate Fellowship. JN is supported by Stanford University
Medical Scientist Training Program grant T32-GM007365. SL acknowledges brownie bites from
Target for providing a crucial fuel source for late night experiment-running.
This website is adapted from
this website,
which was adapted from
this website,
which was in turn adapted from
this website.
Feel free to use this website as a template for your own projects by referencing this!